Configuring high availability
Platform monitors each machine on which the components are running. Each
machine sends a heartbeat as configured in the cluster-config.xml file. All the nodes handle requests in a round-robin
fashion. However, in case of a failover, the remaining nodes in the group continue to
handle the requests ensuring that there is no disruption to the requests and Platform
sends an email to the administrator. Once the failover issue is fixed, the node is up
and running and handles requests as usual.
The diagram below shows a sample architecture for high availability in Platform:
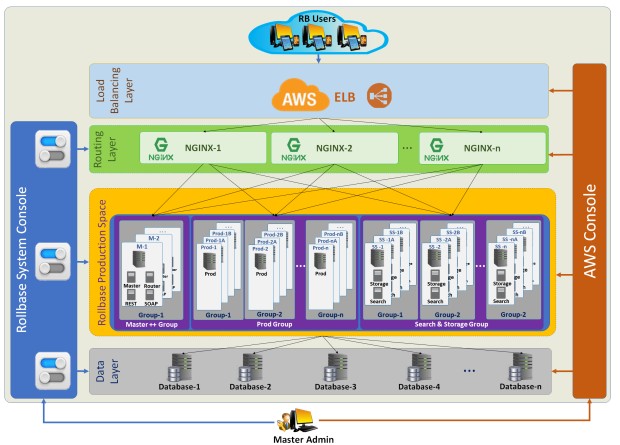
- Load Balancing Layer:
ELB helps an IT team adjust capacity according to incoming application and network traffic. Users enable ELB within a single availability zone or across multiple availability zones to maintain consistent application performance.
ELB ensures that all Platform user requests are routed to the Nginx nodes in the Routing Layer.
- Routing Layer:
The Routing Layer is responsible for routing all the requests to the Platform components in the Platform Production Space. It also serves static content.
- Platform Production Space:
All the Platform components run in the Platform Production Space. For example, in the diagram above, each node in the the Master Group forms a cluster group. Each node contains a Master component. In addition, the Master Group may also comprise Router and REST components. All system admin tasks are performed by the Master component.
Similarly,each node in the ProdGroup also forms a cluster group. Each of these nodes contains a Prod component. The ProdGroup is responsible for handling application development and all end-user interactions. The Search & StorageGroup comprises the search and storage components to handle all search and storage related activities.
Note:Infinite Blue recommends that you install your Router and REST servers on a single computer as it results in faster REST API execution.
- Data Layer:
This layer comprises the entire Platform system data and tenant data.
- Platform System Console:
The Platform System Console provides an overview of system components, system health, logs and performs administrative activities. See System Tab Interface for details.
- AWS Console: Typically, a DevOps member uses the AWS Console to monitor the cluster set-up.
In the diagram, each node is a host in its group.
- Master++Group — Runs the Master server, Router server and REST server
- ProdGroup — Runs the Production server. Note that if you have multiple Production servers, each must run on a different machine.
- Search&StorageGroup — Runs the Storage server and the Search server
- NGINX-1, NGINX- 2, NGINX...n — A high availability NGINX cluster based routing layer.
Understanding cluster-config.xml, master-config.xml and prod-config.xml files in case of a Platform multi-server setup and
High availability configurations.
node-config.json- It is present in every instance which is a part of the cluster.
- In
node-config.json,ServerURLvalue points to the current node IP address.Componentscontains the entries of the existing war files inwebappsfolder.masterDB,updateSharedProps,nodeProps,webProxiesanddatabasessections present in the Master vary based on the components running on the server.
cluster-config.xml- It is present in every instance which is a part of the cluster.
- It lists all the IPs of all instances that are part of the cluster regardless of its type (Master/Prod/Storage/etc).
- This file’s content does not change across instances.
master-cluster-config.xml- It is present in every instance that has a Master war deployed in the cluster.
- This represents an isolated Hazelcast cache only for the Master modules.
- Only when you have a high availability setup, you need to have more than one IP mentioned in the IP list. Otherwise this will have the IP of the machine that this file is present on.
prod-cluster-config.xml- It is present in every instance that has a PRODx war deployed in the cluster.
- The file name is constant as you can deploy only one
prod in a single instance. So regardless of whether you have PROD1,
PROD2 or PRODn deployed, the instance will have a
prod-cluster-config.xml. <instance-name>should be exactly the name given for the prod component in the instance(node-config.json > components).- Only when you have a high availability setup, you need to have more than one IP mentioned in the IP list. Otherwise this will have the IP of the machine that this file is present on.
- On a high availability or multi-server environment and while upgrading to
Platform 5.4, ensure the cluster config XML files
(
master-cluster-config.xml,prod-cluster-config.xml, andcluster-config.xml) are modified by removing the below section from all the Tomcat machines.<map name="rb-*-cache"> <backup-count>3</backup-count> </map>
Also, ensure the below Set Parameter section is removed from the
master-cluster-config.xml.<set name="rb-*-cache"> <backup-count>3</backup-count> </set>
-
In Platform 6.2, in the
cluster-config.xml,master-cluster-config.xml, andprod-cluster-config.xmlfiles of theconfigfolder, the<group>…</group>node must be replaced by<cluster-name>…</cluster-name>.For instance, replace the following:
<group> <name>rb_global</name> <password>rb_global</password> </group>With the following:
<cluster-name>rb_global</cluster-name>
-
In the
cluster-config.xmlfile of theconfigfolder, remove the following attribute from the<replicatedmap>… </replicatedmap>node:<replication-delay-millis>0</replication-delay-millis>
To understand how high availability is configured in Platform, let's consider a multi-server environment as follows.
- Server 1 with IP:
172.21.63.26containing Master, Router, REST components. - Server 2 with IP:
172.16.114.24containing Prod component. - Server 3 with IP:
172.16.81.100containing Search and Storage components.- In every instance, the
webappsdirectory should haveconfig.waralong with the corresponding war files.
- In every instance, the
To configure high availability, perform the steps below:
- Replicate the multi-server set up to ensure each node can be
configured for high availability. That is, the multi-server environment should
now have the following setup.
- Server 1 and Server 4 with IPs:
172.21.63.26;172.21.81.26containing Master, Router, REST components - Server 2 and Server 5 with IPs:
172.16.114.24;172.18.110.24containing Prod component. - Server 3 and Server 6 with IPs:
172.16.81.100;172.16.11.24containing Search and Storage components.- In every instance, the
webappsdirectory should haveconfig.waralong with the corresponding war files.
- In every instance, the
- Server 1 and Server 4 with IPs:
- Update the
cluster-config.xmlto add IP addresses or host names of all the nodes/machines (which are discoverable by other machines) separated by a semi-colon. This file should be part of every node/machine in the cluster.<members>Server1;Server2;Server3;Server4;Server5;Server6</members>
See http://docs.hazelcast.org/docs/latest-development/manual/html/System_Properties.html for more information on hazelcast system properties. - Update
master-cluster-config.xmladd IP addresses or host names of all the master machines.<members>master1;master2</members> - Update
prod-cluster-config.xmladd IP addresses or host names of all the prod machines.<members>prod1a;prod1b</members>Note:- You can extend your multi-server environment to
have more prod servers and configure high availability by
replicating the servers and updating the
prod-cluster-config.xmlto include the new prod nodes. - For example, let's say you added a third prod
server. The
prod-cluster-config.xml, in all prod machines in the group, must be updated to include the IP address or the host name of the third prod server.<members>prod1a;prod1b;prod1c</members> If you want to create a new prod group,
prod 2, you must configure a new node withprod2.warand updatenode-config.json and prod-cluster-config.xmlfiles accordingly. Follow the above step to add more prod servers toprod2group.- When you add new Storage and Search servers, you
must including the server IP addresses in the
cluster-config.xmlto configure them for high availability.
- You can extend your multi-server environment to
have more prod servers and configure high availability by
replicating the servers and updating the
- Update
node-config.jsonin all the instances with the corresponding entries.For example, Server 3
node-config.jsoncontains the entries of Search and Storage as shown below.{ "serverUrl": "http://172.16.81.100:8080", "components": [ { "name": "STORAGE", "type": "STORAGE", "internalRoot": "/storage", "externalRoot": "/storage" }, { "name": "SEARCH", "type": "SEARCH", "internalRoot": "/search", "externalRoot": "/search" }], "nodeProps": { "FontDirs": "", "StorageDir" : "X:/Storage", "LogDir" : "Y:/Logs", "IndexDir": "", "AnalyticsLogDir": "" } } - Install NGINX. See Installing NGINX for more information.
- Configure NGINX. See Configuring NGINX for more information.
- Copy the
private.keyfile from rollbase\config\security folder and paste it into the nginx\conf folder. - Update node-config.json with the NGINX webproxies information.
This enables NGINX for Platform.
"webProxies" : [ { "url": "http://NGINXServerIPAddress:9080" } ]Note: If you want to configure an existing multi-server environment for high availability, you can add an NGINX server by logging into Platform, navigating to , and entering the NGINX webproxies details. - Start the Platform instance.Note: To verify that high availability is configured, in the System Console > System > Components, the Host Name column should display the nodes of the cluster group.

Once you have your environment up and running, you can use the getTopology REST API to get the details of the active
logging Storage server, active Search server, and prod servers (is dedicated or not) and
so on. See getTopology for more information.
While configuring the High Availability environment, use Network File System to ensure that entire data is available for every component. This configuration can be done in node-config.json for every instance.
Example
For the above sample architecture, the following are the changes made to configure high availability.
cluster-config.xml
<members>172.21.63.26;172.16.114.24;172.16.81.100;172.21.81.26;172.18.110.24;172.16.11.24</members>
master-cluster-config.xml
<members>172.21.63.26;172.21.81.26</members>
prod-cluster-config.xml
<members>172.16.114.24;172.18.110.24</members>
node-config.json
"webProxies" : [ { "url": "http://172.20.65.26:9080" } ]
Troubleshooting
As explained earlier in this topic, high availability configurations are made manually in all nodes and as a result of this, there might be some replication issues. You must ensure the following checks are made when servers do not run as expected.node-config.json,cluster-config.xml,master-cluster-config.xml, andprod-cluster-config.xmlare updated as per your architecture.node-config.jsonis identical in all nodes that are a part of prod, Search, or Storage groups.- The hazlecast port is enabled to accept requests. Refer the
<port auto-increment="false">5701</port>tag incluster-config.xml.